
東芝デジタルソリューションズ株式会社ソフトウェア&AIテクノロジーセンター
技監
服部 雅一
IoT/ビッグデータ時代に貢献する自律データ再配置技術を搭載。新たなカタチのデータベース開発!
センサーなどから膨大なデータが集まるIоTの分野では、「中長期的に、データ量がどれだけ増加するかわからない」という厄介なテーマを抱えている。世の中で生み出されるデータ量は爆発的な勢いで増加し続けており、ビッグデータを収納するデータベースは、処理の高速性だけでなく、高い拡張性や信頼性、機能の一貫性までもが要求される。この諸条件を満たすビッグデータ用データベースとして高く評価されているのが、東芝デジタルソリューションズが提供する「GridDB」だ。チーフアーキテクトを務めた服部雅一氏は、いかにしてこの画期的なデータベースの構築に成功したのか――。
時間がないならないなりの成果を素早く提示する
1990年に東芝に入社した服部氏は、当時の上司がたびたび口にしていた「氷山の一角」のたとえ話が今も強く印象に残っているという。
「技術開発の心構えの話で、完璧なものをつくってから完成とするのではなく、出せる部分はいち早く発表して、成果を提示し、機に応じて少しずつ調整、改善するようアドバイスを受けたのです。海面に出ている氷山が〝成果〞や〝製品〞を指し、水面下に隠れている部分が今後開発すべき技術を意味していました。端的にいえば、『時間がなければないなりの結論を出そう』ということです。機能・性能・品質・時間などの条件をすべて満たすことが難しい場合は、時間を優先してまず市場にリリースし、その研究開発を継続させることが大事なのだと教わりました」
GridDBの開発にも、その発想が生かされているという。服部氏がGridDBの開発に着手したのは2012年のこと。驚くべきことに、その翌年には完成に漕ぎつけている。
「GridDBは、『NоSQL』と『SQL』の2つのインターフェイスを備えています。当初は、処理の高速性と高い拡張性に強みを持つNоSQL型データベースとして製品化し、その後、ニーズに応じた強化開発により、SQL型のエンジンも搭載することで、より多くのユーザーが使用できるようにしました」
データベースは、性能を向上させるための手法によって、大きく「スケールアップ」と「スケールアウト」の2つのタイプに分類される。スケールアップとは、CPUやメモリを追加するなどしてデータベースが動作しているサーバ単体の性能を向上させる手法。
一方のスケールアウトは、サーバの台数を増やすことで全体の性能向上を目指す手法である。GridDBは、後者のスケールアウト型に属する。
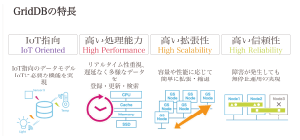
どちらの手法にもメリット・デメリットがあるが、スケールアップはサーバ単体の性能向上という面において物理的な限界がつきまとう。一方、スケールアウトはサーバの数を追加するだけで、データ量の急増に対応できる。もちろんそのためには、データベースの性能がサーバ台数に比例する必要がある。ハードウェアのリソース投入量に対して性能が比例するシステム要素を「スケーラビリティ」といい、このスケーラビリティこそが、データ量が急激に拡大するIоTの分野では重要となる。
一昔前まで、データベースの世界ではSQL型のリレーションデータベース(RDB)が主流だったが、RDBはスケールアウトによる性能向上が難しく、スケーラビリティに難があった。対するNоSQL型 データベースは、データ構造や処理がシンプルなため、スケーラビリティの面で強みを持つことを特徴としている。
「IоT時代のデータベースには、スケーラビリティ、すなわち高い拡張性が求められることは明らかでした。そこで、いち早く製品化して社会に提供するため、GridDBはまずNоSQL型のデータベースとして開発しています。ただ、歴史が古いSQL型はユーザーやエンジニアの人口そのものが多いのが実情です。できればSQLでもGridDBにアクセスしたいという要望が寄せられたため、デュアルインターフェイスの仕様へ強化したのです。この戦略が、高い評価の獲得に寄与したと思います」
ひとくちに「NоSQL型のデータベースを開発した」と言っても、話はそう簡単ではない。ミリ秒単位の周期で発生する膨大な時系列データを扱うことが求められると同時に、各データに矛盾や欠損などを生じさせない一貫性や整合性も要求される。
従前のスケールアウト型データベースでは、複数のサーバをネットワークで接続して大量のデータを扱っていたためデータの分散化が余儀なくされ、そのことがデータの一貫性を保つうえで支障となっていた。
一方で、一貫性を維持しようとするとパフォーマンスの低下を招くなど、IоTシステムへの適用に大きな課題を抱えていたのである。服部氏は、こうした課題を解決するために、「自律データ再配置技術(ADDA)」という技術を開発。この技術によって、データベースサーバの追加等の状況を検知すると、データやコピーのデータベースサーバに対する再配置計画を決定し、サーバ間で高速にデータ転送を行った後、一貫性が取れた状態でデータアクセスの切り替えを行う。この処理を自律的に行うことで、アプリとデータベースサーバの間に位置する管理サーバや仲介サーバなどを取り除くことを可能にした。その結果、通信やデータ変換処理などのコストを大幅削減し、高いデータ一貫性と可用性、高いパフォーマンスを同時に実現したという。服部氏は次のように話す。
「GridDBの肝ともいえるこの自律データ再配置技術の開発では、かつてAI研究に携わっていた知見、経験が大きく生かされているのです」GridDBは、試験運用を経て、14年に商用化。以降、強化開発を継続しながら、エネルギー監視、電力自由化システムや製造現場の効率化など、社会インフラのアプリケーションに適用されており、16年には、基本機能のオープンソース化にも踏み切っている。そして、自律データ再配置技術は、18年に「関東地方発明表彰」を受賞した。
特許公報を読み漁り、独学でデータベースの知識習得に励む
現在、第3次AIブームを迎えているが、服部氏は80年代半ば頃に訪れた第2次AIブームの影響を強く受けた人物である。
「大学院では、推論や学習などAIの研究に夢中でした。当時は景気がよく、就職は引く手あまたでしたが、AIの研究ができる点に魅力を感じて東芝に入社したのです。配属先では、AI応用システムを担当。事例ベース推論を駆使した中型モーターの設計支援システムやプラントの自動監視システムの構築などを手がけていました」
転機が訪れたのは、90年代後半のこと。この頃、研究の柱がAIからデータベースへと移った。服部氏は、「〝フレーム問題〞と呼ばれるAIの技術的課題に突き当たったことが大きく影響しています」と述懐する。
「ディープラーニング以前のAIは、何もかも人の手によるお膳立てが必要でした。AIにデータの処理をさせようにも、当時のAIは今のように〝外界〞とつながっておらず、外部にあるデータや素材をエンジニアが地道に移植したうえで、さらにルール化を行う必要がありました。外部のデータをいかにしてAIに取り込んで活用していくかを考えた時に、初めてデータベースの重要性を認識したのです」
それまでAIをメインに研究してきた服部氏にとって、当然ながらデータベースは未知の領域だった。
「独学での勉強を考えたのですが、当時はデータベースについて網羅した書籍やテキストがほとんどなく、指導してくれる人も身近にいませんでした」そこで服部氏は、図書館に通って「特許公報」を読み漁る日々をスタートさせる。
「データベース関連の特許をひたすら読み込んでいきました。今はインターネットで閲覧できますが、当時はページをめくり続けて、十数年分の特許公報を読み込む以外に手がなかった。我ながら、この時は頑張ったと思いますね(笑)。もしかすると別のアプローチがあったかもしれませんが、とにかく夢中でしたから」
データベースに関して一定の知見を得たと感じた服部氏は、XMLデータを格納して高速検索するデータベースの研究開発をスタートさせる。97年のことだった。そして99年に試作品を完成させたタイミングで、ある話が舞い込んだ。
「当時の日本では、〝社内ベンチャー〞が流行していました。ベンチャーキャピタルの後押しもあり、私は上司とITベンチャーを興しかけたのですが、最終的に東芝で製品化を検討してもらえることになりました」
ただ、試作品そのままではとても使いものにならなかったという。
「僕の知識不足が原因です。東芝の府中工場で設計を検証してもらったところ、現場からそれこそ頭ごなしにけなされました。データベースの経験者にいわせると、我々がつくったものは検索エンジンであり、データベースと呼ぶ域に達していないということでした」
挫折を経験したが、服部氏はめげずに工場や研究所の担当者とともに改良と研鑽を重ね、05年に晴れて製品化に漕ぎつけた。その製品は現在も東芝の製品ラインナップに名を連ねている。
「紆余曲折はありましたが、失敗を新たな課題発見とする東芝の社風が幸いしました。おかげで鍛えられましたし、この経験がGridDBの開発に確実に生かされています」
まず自分でやってみる。自分にできないことは他者にも押しつけない
現在、服部氏は東芝デジタルソリューションズ株式会社のソフトウェア&AIテクノロジーセンターで技監を務めている。技監とは、技術者の上位職に該当するポジションである。
「GridDBの強化開発は続けていきますが、今後は、もう少し大局的な立場で技術や物事を俯瞰してみたい気持ちがあります。だからといって、マネジメントに専念したいわけではありません。根は技術者ですから、これからも手は動かし続けたい。AIの分野で何か大きな仕事を、という野望はあります。ただ、必ずしも最先端の分野や技術にこだわる必要はないのです。
最先端分野は競争も激しく、安易に飛びつくと差異化が難しくなりますから。その点は注意深く見極める必要があると考えています」
最後に服部氏は、自身の経験を踏まえて、後進に向けて次のようなエールを送ってくれた。
「自分にできないことを他者に押し付けても、うまくいきません。『まずは自分でやってみること』です。開発でいえば、自分の手で設計書をきちんとまとめてみて、道筋が見えたところで初めて、人に任せます。思想やコンセプトを明示して依頼することが大切だと考えます。XMLデータベースやGridDBの開発でも、僕はそのやり方を貫いてきました。システムやソフトウェアは実に〝素直〞ですから、曖昧でいい加減な思想やコンセプトに基づいてつくり始めると、それなりに〝動いた感じ〞にはなるものの、トラブルが続発します。それを防ぐには、中身や手法をとことん突き詰めておくことが不可欠なのです。そのためには、自分で手を動かしておくことが欠かせないと思うのです」

東芝デジタルソリューションズ株式会社
設立/2003年10月1日
従業員数/9200人(連結:2018年7月末現在)
所在地/川崎市幸区堀川町72-34
コメント